目前各种类型的缓存都活跃在成千上万的应用服务中,还没有一种缓存方案可以解决一切的业务场景或数据类型,我们需要根据自身的特殊场景和背景,选择最适合的缓存方案。缓存的使用是程序员、架构师的必备技能,好的程序员能根据数据类型、业务场景来准确判断使用何种类型的缓存,如何使用这种缓存,以最小的成本最快的效率达到最优的目的。
《架构设计那些事儿–缓存那些事儿》系列共分六章:
- 架构设计那些事儿–缓存那些事儿(一),缓存的前世今生
- 架构设计那些事儿–缓存那些事儿(二),缓存设计模式
- 架构设计那些事儿–缓存那些事儿(三),缓存性能和一致性的最佳实践
- 架构设计那些事儿–缓存那些事儿(四),缓存穿透、 缓存雪崩 和 缓存击穿
- 架构设计那些事儿–缓存那些事儿(五),布隆过滤器详解
- 架构设计那些事儿–缓存那些事儿(六),redis
布隆过滤器
本质上布隆过滤器(Bloom Filter)是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 某样东西一定不存在或者可能存在。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
可以一句话总结:
- 如果Bloom Filter告诉你某个数据不存在,那么它一定不存在。
- 如果Bloom Filter告诉你某个数据存在,那么它不一定存在。
然后你可能要问了,他都不一定存在了,那它有什么用。它虽然不保证100%存在,但是这个误判率却是可以控制的,一般根据场景你可以设置一个可以接受的错误率,比如 0.0001(万分之一),0.00001(十万分之一)。在很多场景下,这个概率是可以接受的。在这些场景下,它就有用武之地了。
而它的优点非常明显,就是极少的空间占用,一般比正常存所有数据可以节省90%左右以上的内存。
如果有人对具体的误判率怎么用数学公式推算出来的算法感兴趣。下面的详解部分会给出推导的链接。
实际场景
根据实际场景来让大家了解一下在什么场景下需要布隆过滤器,它又解决了什么问题。
我们有一个需求,是判断任意的两个userid有没有聊过天。即(useridA, useridB)是否聊过天,来决定前端场景是否展示对方的username。我们最初的设计是放在Redis里面,存放的格式是:
1 | Redis String |
我们的Userid是int32的递增值,现在已经有10位整数。(eg: 1212341234)。所以这个key至少有22字节。
但是最终统计出来,我们的userid聊天的唯一Key:(useridA, useridB) 有4 Billion(40亿)的数据。
也就是我们至少需要存40亿的数据到Redis。
内存预估
Redis使用SDS的数据结构来储存字符串。格式简化后如下图所示:
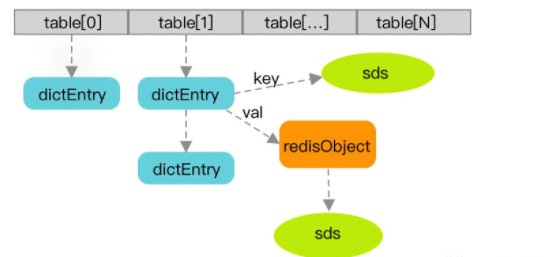
- Key占用储存空间:Key(22)+SDS(9)=31;
- Value占用储存空间:Value(1)+SDS(9)+redisObject(16)=26;
总内存占用:(31+26) * 4 billion = 228G。
我们预估未来还有10倍的增长空间,那就是2.28T。
当然这只是粗略的估计,Redis有更加复杂详细的规则来优化内存占用。
我自己尝试过插入一百万的数据到Redis,实际内存占用跟我的计算公式差不多。
所以这个内存占用是非常夸张的,我们需要用技术方案来优化这个内存占用。
这个时候我们就需要解决内存的占用过多的问题,布隆过滤器(Bloom Filter)闪耀登场。
布隆过滤器详解
布隆过滤器实际上是一个很长的二进制向量和一系列随机映射函数,二进制大家应该都清楚,存储的数据不是0就是1,默认是0。
主要用于判断一个元素是否在一个集合中,0代表不存在某个数据,1代表存在某个数据。布隆过滤器使用k个hash函数,每个哈希函数映射到Bit位的某一位,这样当k个位都为1的时候,我们认为这个元素存在。如图所示: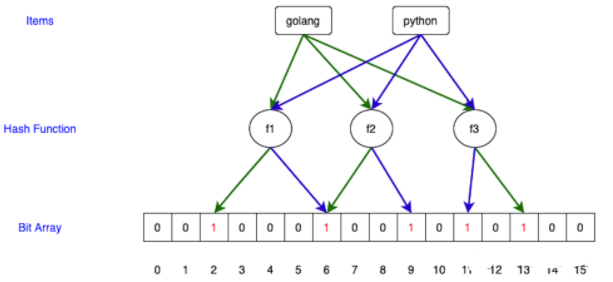
使用流程
1,Set流程
1.设置K个hash函数. (f1, f2, f3, … fk).
2.对数据 (eg: golang) 进行hash,得到k个值. (2,6,11, …)
3.在Bit Array指定的位置设置为1.
2,Check流程
1.使用K个hash函数得到K个值。
2.在Bit Array上各个位置查看对应的值是否为1.
3.任何一个值为0,则此元素不存在。
4.所有的值都为0,则我们认为此元素存在。
布隆过滤器计算器
我们首先定义以下布隆过滤器的相关变量。
- n: 总的数据量的数量大小。
- p: 误判率的大小 (0.01 means 1%)
- k: hash函数的数量
- m: 需要的Bit数组的Bits空间量。
我们可以把 n,p 作为输入,就可以得到 k, m 作为输出。也可以使用 n,p,k 作为输入,可以得到 m 作为输出。
这里是在线布隆过滤器计算器 (布隆过滤器计算器)[https://hur.st/bloomfilter/ ]
下图是我计算出来的值。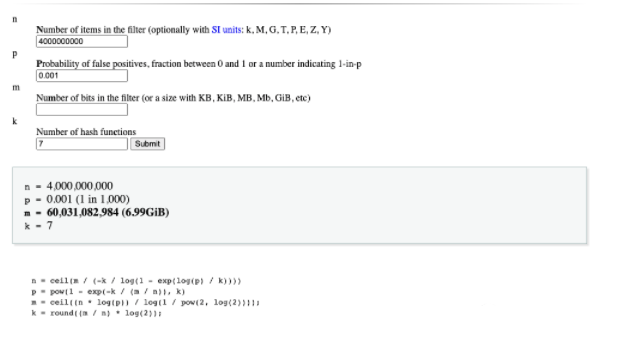
可以对比最初的设计方案,4 Billion的数据, 0.001的错误率。只需要7GB的内存。7/228=3%, 差不多节省了97的内存空间。
误判率
你可能会好奇,误判率是什么。因为我们使用的是hash映射。不同的数据经过不同的hash函数是有几率映射到同一个位置的。例如:
1 | f1(golang)=2, f2(golang)=6, f3(golang)=11 |
当我们把 python, jave, cpp 插入到Bit Array后,位置(2,6,11)的值都为1。
这个时候我们检查 golang 是否存在,由于这几个位置的值都为1, 所以系统会告诉我们 golang 存在。
实际上我们并没有插入 golang, 这就产生了误判。
所以我们回到最初的定义:
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 某样东西一定不存在或者可能存在。
- 如果布隆过滤器告诉你个数据不存在,那么它一定不存在。
- 如果布隆过滤器告诉你某个数据存在,那么它可能存在。(也可能不存在,误判)
布隆过滤器实现
1,Redis内实现
Redis在4.0版本推出了 module 的形式,可以将 module 作为插件额外实现Redis的一些功能。官网推荐了一个 RedisBloom[2] 作为 Redis 布隆过滤器的 Module。它主要使用的命令包含两个命令:
- 1.bff.add key value //添加某个value
- 2.bff.exists key value //判断某个value是否存在。
1.1 RedisBloom 安装
Redis不是默认就有,需要安装module才可以使用其命令。未安装之前提示:可以使用docker安装,也可以使用源码安装:这里只展示一下docker安装并测试简单指令,有需要源码安装的可以网上查看教程。1
2127.0.0.1:6379> bf.add bloom_key bloom_value
(error) ERR unknown command `bf.add`, with args beginning with: `bloom_key`, `bloom_value`,
1.拉镜像
2.docker运行redisbloom
3.进入docker
4.执行redis-cli
1 |
|
Redis的Bloom Filter内部使用Redis的Bitmap来实现。
Bitmap基于最小的单位bit进行存储,所以非常省空间。
redis中bit映射被限制在512MB之内。
有兴趣可以看一下Redis的官方文档。Redis BloomFilter
1.2 go操作RedisBloom
1 | func bloomFilter(ctx context.Context, rdb *redis.Client) { |
2,go编码实现布隆过滤器
由于Redis的Bloom Filter并非Redis原生自带的功能,需要安装module才能使用,很多时候生产环境使用的云服务并不一定完美支持,所以需要一个自己实现的布隆过滤器,在这里就不重复造轮子了,详见开箱即用的bloom,非常方便。